Wednesday, November 16, 2011
How Can user Ranking Function Use in Sql Server?
ROW_NUMBER()
The ROW_NUMBER function simply assigns sequential numbering to the records of a result-set or to the records within groups of a result-set. You can create these groupings (partition the records) using the PARTITION BY clause. The syntax for ROW_NUMBER function is:
ROW_NUMBER() OVER ( [PARTITION BY partition_value_expression , ... [ n ]] ORDER BYorder_value_expression , ... [ n ])
- OVER clause is required in all the ranking functions and with that you specify the partitioning and ordering of records before the ranking functions are evaluated. If you don't specify it, you will get an error similar to "Incorrect syntax near 'ROW_NUMBER', expected 'OVER'."
- PARTITION BY clause is not mandatory and if you don't specify it all the records of the result-set will be considered as a part of single record group or a single partition and then ranking functions are applied. When you specify a column/set of columns with PARTITION BY clause then it will divide the result-set into record groups/partitions and then finally ranking functions are applied to each record group/partition separately and the rank will restart from 1 for each record group/partition separately.
- ORDER BY clause is mandatory and if you don't specify it you will get an error similar to "The ranking function "ROW_NUMBER" must have an ORDER BY clause.". With this clause you specify a column or a set of columns which will be used to order the records within a result-set or within record groups/partitions of a result-set. Please note you can specify only those columns which are being made available by the FROM clause of the query. Also, you can not specify an integer to represent the position of a column, if you do so you will get "Windowed functions do not support integer indices as ORDER BY clause expressions." error.
Script #1 has two queries (All the examples in this tip were run against the AdventureWorks database), the first query does not use the PARTITION BY clause and hence all the records are considered to be in a single partition and then records are sorted by BirthDate column and finally the sequential numbering is assigned.
The second query, as you can see, creates a partition (group of rows) on the basis of ManagerID column and then assigns sequential numbering to each row within each partition (group of rows) separately.
Script #1 - ROW_NUMBER Function |
--This script assign sequential number to each row--This script partitions the result-set into multiple 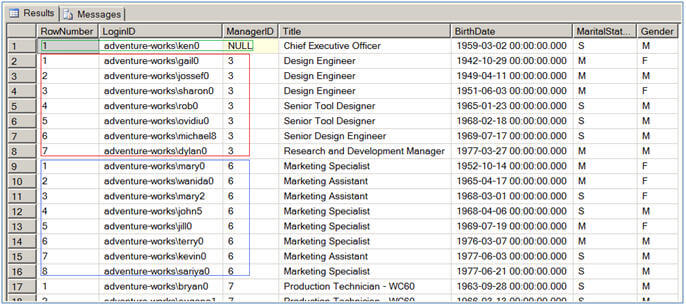 |
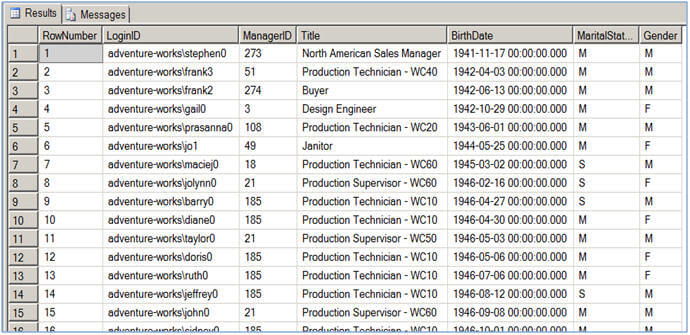
Sometimes you might want to have sequential numbering of records without sorting the result-set (might be for performance reasons) in other words you want to have numbering on the records as they are stored in the database. You can use the second script provided in the Script #2 table below. Have a look at the execution plans generated for these two queries from Script #2. Note the first query uses the SORT physical operator (which itself is 65% of the query) which is an expensive operator, because of its nature of being a blocking and memory consuming operator. If you use a column or set of columns in the ORDER BY on which there is a clustered index, the Query Optimizer will not include the SORT operator, but rather it will use the clustered index which has already sorted the data. For example, if you replace "ORDER BY BirthDate" to "ORDER By EmployeeID" (which has a clustered index) the optimizer will not use the SORT operator.
Script #2 - ROW_NUMBER without SORT |
--This script assign sequential number to each row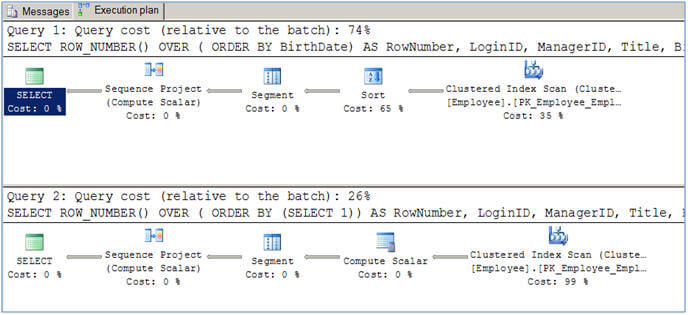 |
The inclusion of the ROW_NUMBER function (and other ranking functions) simplifies many query for which we had to write several lines of code. For example you can delete duplicate records from a table with just one query. Refer to "Different strategies for removing duplicate records in SQL Server" for more details.
RANK()
The RANK function instead of assigning a sequential number to each row as in the case of the ROW_NUMBER function, it assigns rank to each record starting with 1. If it encounters two or more records to have the same ORDER BY <columns> values, it is said to be a tie and all these records get the same rank. For example, in the first image below, you can see the first and second records have the same "Accountant" value in the Title column and hence they both got the same rank.
The second query in Script #3, shows you an example where the result-set has been partitioned on the basis of the Gender column and then ranking is assigned in each group separately. The syntax for the RANK function is very much similar to the syntax of the ROW_NUMBER function as discussed above:
RANK() OVER ( [PARTITION BY partition_value_expression , ... [ n ]] ORDER BY order_value_expression, ... [ n ])
Script #3 - RANK Function |
--This script assign rank to each row of result-set which is--This script assign rank to each row of a partition (group of records) 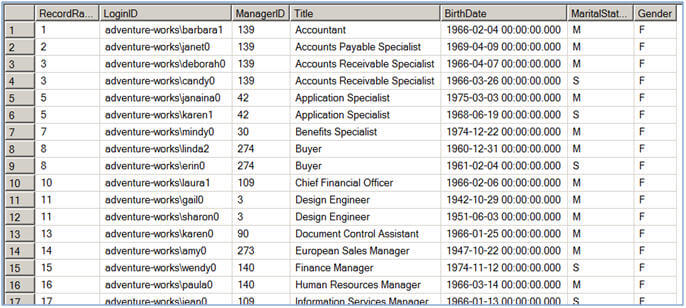 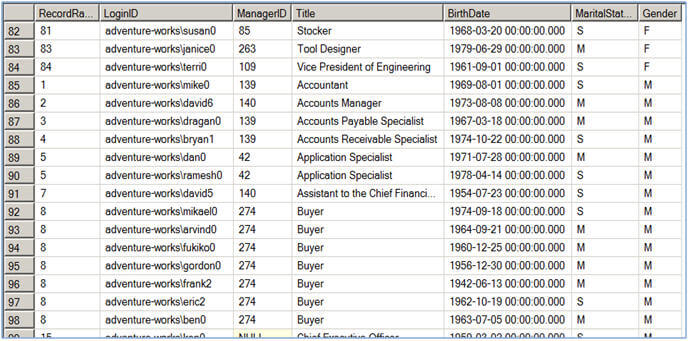 |
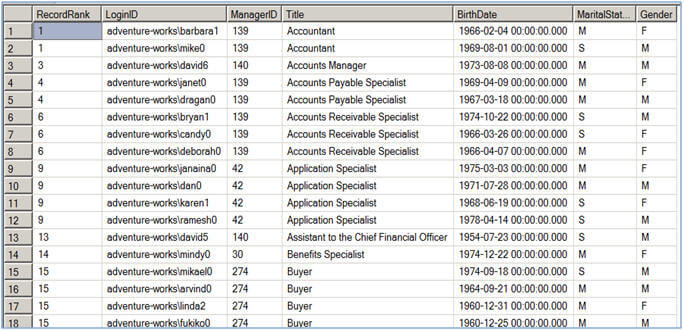
If you notice the ranking is not consecutive with the use of the RANK function; that is because the RANK function ranks records of the result-set sequentially starting from 1. When it finds a tie it assigns the same rank to the all the records in the tie, but still keeps incrementing the record counter so the next record will get a new rank which would be (previous rank + no of records in the current tie + 1) . For example in the first image of Script #3 you can see that the first and second record has "Accountant" title so they both have the same rank i.e. 1, but the next record has a rank of 3 ( 0 + 2 + 1 ).
